プロンプトエンジニアリングでOmamori Gemの精度向上を目指す
AI診断の精度向上
先日公開したOmamoriについて、精度がいまいち、不安定という問題があったので、改善を目指してみます。
Omamoriについては過去記事を参照してください。
rira100000000.hatenablog.com
temperatureの設定
精度向上を目指すうえで厄介なのが、現状だと毎回診断結果が異なることです。
つまり、プロンプトエンジニアリングで精度向上を目指しても、脆弱性の発見できる数が毎回ばらけると本当に効き目のある工夫が行えたのか判断できません。
ここで役に立つのがtemperatureのパラメータ設定です。
temperatureは0~1の値で、値が大きいほどgeminiの回答にバラつきが出るようになります。
例えば創作活動をしていて色々なアイデアが欲しい場合は高く設定することでより多様な回答を得られます。今回は同じインプットなら毎回同じ診断結果が欲しいので、0に設定したいです。
ruby-gemini-api Gemでtemperatureを設定する機能が無かったので早急に利用可能に修正を行いました。
そしていざtemperature: 0でデモファイルに対して数回omamori scan --aiしてみます。
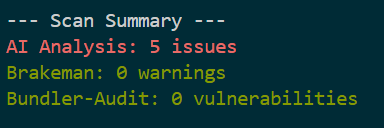
毎回発見できる数が5個になりました。
ここからプロンプトを変更することでさらに発見できる脆弱性を増やすことを目指します。
Chain-of-Thought(CoT:思考の連鎖)
CoTはAIに問題解決の過程を明示的に示す手法です。「ステップバイステップで考えてください」と促すことで、AIは思考プロセスを段階的に表現し、複雑な問題を分解して解決できるようになります。
システムプロンプトに「Think step by step.」という文言を加えて、再度scanしてみます。

なんと、診断結果が減りました。
ここで診断できなくなったのは SSRF脆弱性でした。
しかし、今回追加したのはステップバイステップで考えなさいという命令だけで、具体的にどのように考えればよいか、ということまでは示していません。これはゼロショットCoTと呼ばれる手法で、むしろAIを混乱させたと考えられます。
ここで、脆弱性のリストにどのように考えて診断すればいいかを追加します。
これまでの脆弱性のリストは脆弱性の名前と危険性を解説するだけの、以下のような内容でした。
ssrf: "Server-Side Request Forgery (SSRF): The server makes HTTP requests to an arbitrary destination supplied by the user, potentially exposing internal resources or metadata."
ここにSSRFを発見するための手順を加え、以下のように変更してみます。
ssrf: "Server-Side Request Forgery (SSRF): The server makes HTTP requests to an arbitrary destination supplied by the user, potentially exposing internal resources or metadata. Detection steps: 1) Identify code that makes network requests (HTTP, TCP, etc.). 2) Check if the URL or destination can be influenced by user input. 3) Verify if there is proper validation of user-supplied URLs or IPs to prevent access to internal resources. 4) Look for use of libraries like Net::HTTP, open-uri, rest-client, faraday, or HTTP clients where the URL is constructed dynamically. 5) Check if the code restricts requests to only allowed domains or IP ranges.",
これが具体的な例を1つ示す、ワンショットCoTと呼ばれる手法です。
プロンプト改善の結果の確認を行います。

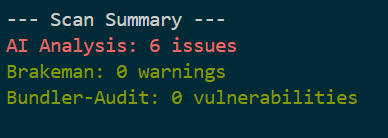
SSRFの発見に成功しました。
不思議なことにSSRFのステップバイステップ診断方法を教えたらCode Injectionも新たに発見できたようです。

これはステップバイステップで考える、ということの解像度が上がった影響かもしれません。
ワンショットCoTがプラスに働くことが確認できたので、Omamoriが診断対象にしている35件の脆弱性それぞれに検出の手順を追加し、scanを行います。

今度はCode Injectionが発見されなくなりました。
dangerous_evalの解説はとても分かりやすいはずですが、何故このようなことが起きたのでしょう。
プロンプトの長さを考える
ここで気になったのは、これまで全てのファイルをまとめてスキャンにかけていたのですが、eval脆弱性のあるファイルだけをスキャンするとどうなるのかということです。
eval脆弱性を持つファイルだけをscanしてみます。

今度は脆弱性診断に成功しました。
他のファイルにも試してみましたが、ファイル一つずつに診断を行った方が明らかに精度が高くなるようです。
これはコンテキストが長くなるほどコード一つずつへの集中力が落ちる、というような現象が起きているように感じます。
Omamoriはデフォルトでは一度に読み込ませるコードを7000文字に制限しています。
この値はオプションでchunk_sizeを指定することで変更できます。chunk_sizeを2000に変更し、scanを行ってみます。

飛躍的に性能が向上しました。(びっくり…)
コンテキストが大きすぎるとハルシネーションを起こしやすくなる、といった話は聞いたことがありますが、コード7000文字+命令1000文字のプロンプトは完全に大きすぎたようです。
まとめ・感想
プロンプトを適切な内容、長さにするだけで、脆弱性診断性能が大きく向上しました。
Omamoriでもchunkサイズの調整とワンショットCoTを採用しました。
今回プロンプトエンジニアリングに着手したのはGoogleのプロンプトエンジニアリング白書Prompt Engineering | Kaggleを読んだことがきっかけだったのですが、ここまでの成果が得られるとは思っていなかったので驚きでした。
個人的にはプロンプトエンジニアリングはAIが賢くなればいずれ不要になる(勝手に意図を組んでくれるはず)という考えなのですが、現時点では抜群の効き目があることがわかりました。
今後も改善手法を探ってOmamoriを成長させていきたいと思います。